TanStack 是 Tanner Linsley 发起的跨框架工具库系列,最初叫 React Query,后来演变成支持 React、Vue、Svelte、Angular 等多框架的生态系统。它包含:
- TanStack Query:异步状态管理,处理数据获取、缓存、同步
- TanStack Table:Headless 表格逻辑库(无 UI,纯逻辑)
- TanStack Router:类型安全的路由库
- TanStack Virtual:虚拟滚动处理海量列表
- TanStack Form:跨框架表单管理
其中 TanStack Query 是最出名的产品,下面重点讨论它。
为什么需要 TanStack Query
写过 useEffect + fetch 的人都知道,手动管理异步数据很烦:
// 传统方式
function Profile() {
const [data, setData] = useState(null)
const [loading, setLoading] = useState(true)
const [error, setError] = useState(null)
useEffect(() => {
fetch('/api/user')
.then(res => res.json())
.then(setData)
.catch(setError)
.finally(() => setLoading(false))
}, [])
if (loading) return <div>Loading...</div>
if (error) return <div>Error: {error.message}</div>
return <div>{data.name}</div>
}问题在于:
- 每个组件都要写三个状态(data, loading, error)
- 没有缓存,切换路由再回来会重新请求
- 断网后无法自动重试
- 多个组件请求同一接口会发多次请求
所以出现了SWR 和 TanStack Query 来解决这些问题,两个核心思路差不多——都用缓存、自动重验证、乐观更新这些策略来管理服务端状态,但 TanStack Query 功能更全面一些,比如内置的无限滚动、更强大的 Devtools、以及对 Vue、Solid 等框架的跨平台支持,而 SWR 更轻量,API 设计极简,由 Vercel 团队维护,SWR 是”简单至上”,适合快速上手;TanStack Query 是”功能完备”,适合复杂应用。
SWR vs TanStack Query
先看 SWR 的方式:
import useSWR from 'swr'
function Profile() {
const { data, error, isLoading } = useSWR('/api/user', fetcher)
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error</div>
return <div>{data.name}</div>
}TanStack Query 的方式:
import { useQuery } from '@tanstack/react-query'
function Profile() {
const { data, error, isLoading } = useQuery({
queryKey: ['user'],
queryFn: () => fetch('/api/user').then(res => res.json())
})
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error</div>
return <div>{data.name}</div>
}从上面两个例子来看,表面上看差不多,但细节上:
| API 风格 | 缓存策略 | Mutation | DevTools | 离线支持 | |
|---|---|---|---|---|---|
| SWR | 简洁,第一个参数是 key | 默认激进,适合实时性要求高的场景 | 需要手动触发 revalidate | 无官方工具 | 基础支持 |
| TanStack Query | 配置对象,更明确 | 更灵活,可精细控制 | 内置 useMutation 钩子 | 强大的可视化调试工具 | 内置 Offline Mutations 队列 |
Query Key 的作用
这是 TanStack Query 最核心的设计:Query Key 是缓存的唯一标识。
// 基础用法:字符串数组
useQuery({
queryKey: ['user'],
queryFn: fetchUser
})
// 带参数:数组元素会序列化为缓存 key
useQuery({
queryKey: ['user', userId],
queryFn: () => fetchUser(userId)
})
// 复杂查询:数组可以嵌套对象
useQuery({
queryKey: ['users', { page: 1, limit: 10, filter: 'active' }],
queryFn: ({ queryKey }) => {
const [, params] = queryKey
return fetchUsers(params)
}
})为什么用数组?
- 自动缓存隔离:不同参数自动对应不同缓存
// 这两个查询互不影响,各自缓存
useQuery({ queryKey: ['user', 1], queryFn: () => fetchUser(1) })
useQuery({ queryKey: ['user', 2], queryFn: () => fetchUser(2) })- 批量失效缓存:可以用前缀匹配
// 让所有 user 相关的查询失效
queryClient.invalidateQueries({ queryKey: ['user'] })
// 只让特定用户的查询失效
queryClient.invalidateQueries({ queryKey: ['user', userId] })- 依赖追踪:数组变化会自动重新请求
function UserPosts({ userId }) {
// userId 变化时自动重新请求
const { data } = useQuery({
queryKey: ['posts', userId],
queryFn: () => fetchPosts(userId)
})
}对比 SWR,SWR的 key 是字符串或函数:
// SWR 需要手动拼接 key
useSWR(`/api/user/${userId}`, fetcher)
// 或者用函数返回数组,实际上也是序列化成字符串😂
useSWR(() => ['/api/posts', userId], fetcher)TanStack Query 的数组方式更直观,且原生支持复杂对象。
离线请求的处理
TanStack Query 内置了 Offline Mutations 队列,断网时的操作会被缓存,恢复网络后自动重试。
function TodoApp() {
const queryClient = useQueryClient()
const addTodo = useMutation({
mutationFn: (newTodo) =>
fetch('/api/todos', {
method: 'POST',
body: JSON.stringify(newTodo)
}).then(res => res.json()),
// 离线时的乐观更新
onMutate: async (newTodo) => {
// 取消正在进行的查询,避免覆盖乐观更新
await queryClient.cancelQueries({ queryKey: ['todos'] })
// 保存旧数据用于回滚
const previousTodos = queryClient.getQueryData(['todos'])
// 乐观更新 UI
queryClient.setQueryData(['todos'], (old) =>
[...old, { ...newTodo, id: Date.now(), status: 'pending' }]
)
return { previousTodos }
},
// 请求失败时回滚
onError: (err, newTodo, context) => {
queryClient.setQueryData(['todos'], context.previousTodos)
},
// 成功或失败后都重新获取
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ['todos'] })
},
// 网络恢复后重试配置
retry: 3,
retryDelay: attemptIndex => Math.min(1000 * 2 ** attemptIndex, 30000)
})
return (
<button
onClick={() => addTodo.mutate({ title: 'New Todo' })}
disabled={addTodo.isPending}
>
{addTodo.isPending ? 'Saving...' : 'Add Todo'}
{/* 显示离线状态 */}
{addTodo.isPaused && ' (Offline - will retry)'}
</button>
)
}关键说明:
- 乐观更新:
onMutate中立即更新 UI,不等服务器响应 - 自动回滚:请求失败时恢复旧数据
- 队列机制:离线时 mutation 会进入队列,恢复网络后按顺序执行
- 状态追踪:
isPaused可以判断是否在离线等待
如果是SWR实现类似功能,需要手动管理:
// SWR 需要自己处理离线逻辑
const { data, mutate } = useSWR('/api/todos', fetcher)
const addTodo = async (newTodo) => {
const optimisticData = [...data, newTodo]
// 乐观更新
mutate(optimisticData, false)
try {
const result = await fetch('/api/todos', {
method: 'POST',
body: JSON.stringify(newTodo)
})
mutate() // 重新获取
} catch (error) {
// 手动回滚
mutate(data, false)
}
}DevTools 的能力
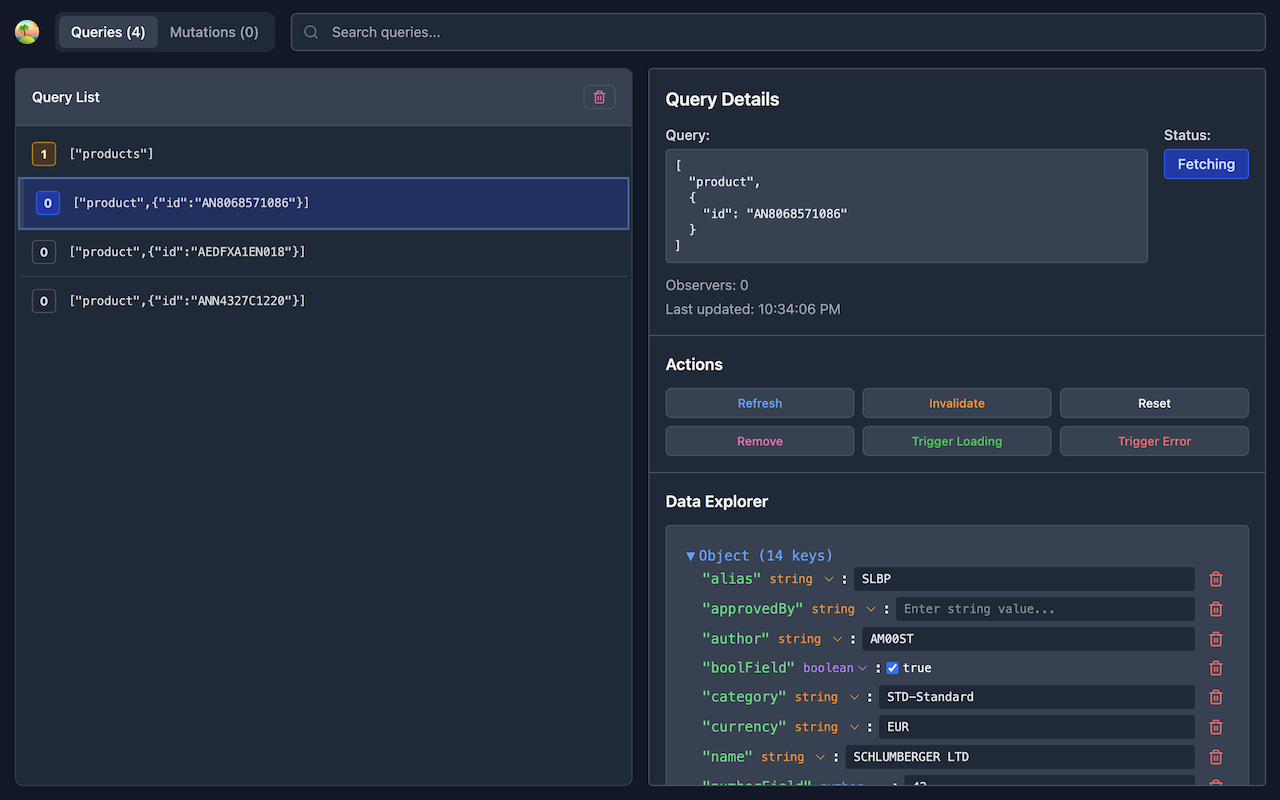
TanStack Query 的 DevTools 是提供超级多的功能,简直是可视化调试的利器:
function App() {
return (
<QueryClientProvider client={queryClient}>
<YourApp />
{/* 开发环境中默认显示在左下角 */}
<ReactQueryDevtools initialIsOpen={false} />
</QueryClientProvider>
)
}核心功能:
1. 实时查看所有查询状态
可以看到:
- 所有活跃的 Query Key 和对应数据
- 每个查询的状态(fresh, fetching, stale, inactive)
- 缓存的过期时间倒计时
- 查询的触发次数和最后更新时间
[users] - fresh (30s)
├─ data: [{ id: 1, name: 'Alice' }, ...]
├─ status: success
└─ fetchStatus: idle
[user, 1] - stale
├─ data: { id: 1, name: 'Alice', email: '...' }
├─ status: success
└─ fetchStatus: idle
[posts, { userId: 1 }] - fetching
├─ data: undefined
├─ status: loading
└─ fetchStatus: fetching
2. 手动操作缓存
- Refetch:点击某个查询可以手动触发重新请求
- Invalidate:让缓存失效,下次访问时自动重新请求
- Remove:直接删除缓存
- Reset:重置到初始状态
实际场景:测试”用户修改头像后列表是否更新”,可以直接在 DevTools 中 invalidate ['users'] 查询。
3. 查看 Mutation 历史
所有 mutation 操作(POST、PUT、DELETE)都会被记录:
Mutations (3)
├─ updateUser - success (2s ago)
│ └─ variables: { id: 1, name: 'Bob' }
├─ deletePost - error (5s ago)
│ └─ error: "Network error"
└─ createTodo - paused (offline)
└─ variables: { title: 'New Todo' }
点击每个 mutation 可以看到:
- 传入的参数(variables)
- 返回的数据或错误
- 重试次数和时间
- 是否在离线队列中
4. 调试缓存策略
可以实时看到 staleTime 和 cacheTime 的效果:
useQuery({
queryKey: ['user'],
queryFn: fetchUser,
staleTime: 5000, // 5 秒内认为数据新鲜
cacheTime: 30000 // 缓存保留 30 秒
})在 DevTools 中会看到:
- Fresh 状态倒计时(5s → 4s → 3s…)
- 变成 Stale 后,组件重新挂载会触发后台更新
- Inactive 状态倒计时(30s),时间到了缓存被清除
这对于调整缓存策略非常有用,可以直观看到不同配置的效果。
5. 性能分析
DevTools 会显示每个查询的:
- 请求次数(避免重复请求)
- 平均响应时间
- 缓存命中率
比如发现某个查询触发了 10 次,可能是依赖项设置有问题。
对比总结
选 SWR 的场景: 项目简单,不需要复杂的 mutation 逻辑; 需要快速上手,学习成本低
选 TanStack Query 的场景: 有复杂的离线操作需求, 需要精细控制缓存策略; 需要强大的调试工具. 多框架支持(Vue、Svelte 等)
TanStack Query 功能更完备,SWR 更轻量。核心差异在于:TanStack Query 把”数据请求”当作一个完整的状态来管理,而 SWR 更像是在 useSWR 钩子上做增强。