K8s(Kubernetes)本质上是一个容器编排平台,解决了”如何在集群上管理成百上千个容器”的问题。如果你用过 Docker,那 K8s 就是帮你自动化”启动、监控、重启、扩容”这些操作的工具。
这篇笔记的目标:在30分钟内理解 K8s 核心概念,并能跑起第一个应用。
一个餐厅类比帮你理解 K8s
| K8s 概念 | 类比 | 一句话 |
|---|---|---|
| Pod | 厨师 | 真正干活的人(跑容器) |
| Deployment | 排班表 | 规定”需要几个厨师上班” |
| StatefulSet | 固定工位厨师 | 每个厨师有固定编号和专属工具柜 |
| DaemonSet | 店内保安 | 每个分店必须有一个,不多不少 |
| Job/CronJob | 临时任务 | 月底盘点(一次性)/每日清洁(定时) |
| Service | 出餐口 | 顾客(流量)从这里取餐,不管哪个厨师做的 |
| ConfigMap | 菜谱 | 公开的配方(调料比例、烹饪步骤) |
| Secret | 秘方 | 保密的配方(祖传秘方锁在保险柜里) |
| Namespace | 分店 | A 店的混乱不影响 B 店 |
| HPA | 灵活用工 | 忙了临时招人,闲了裁员 |
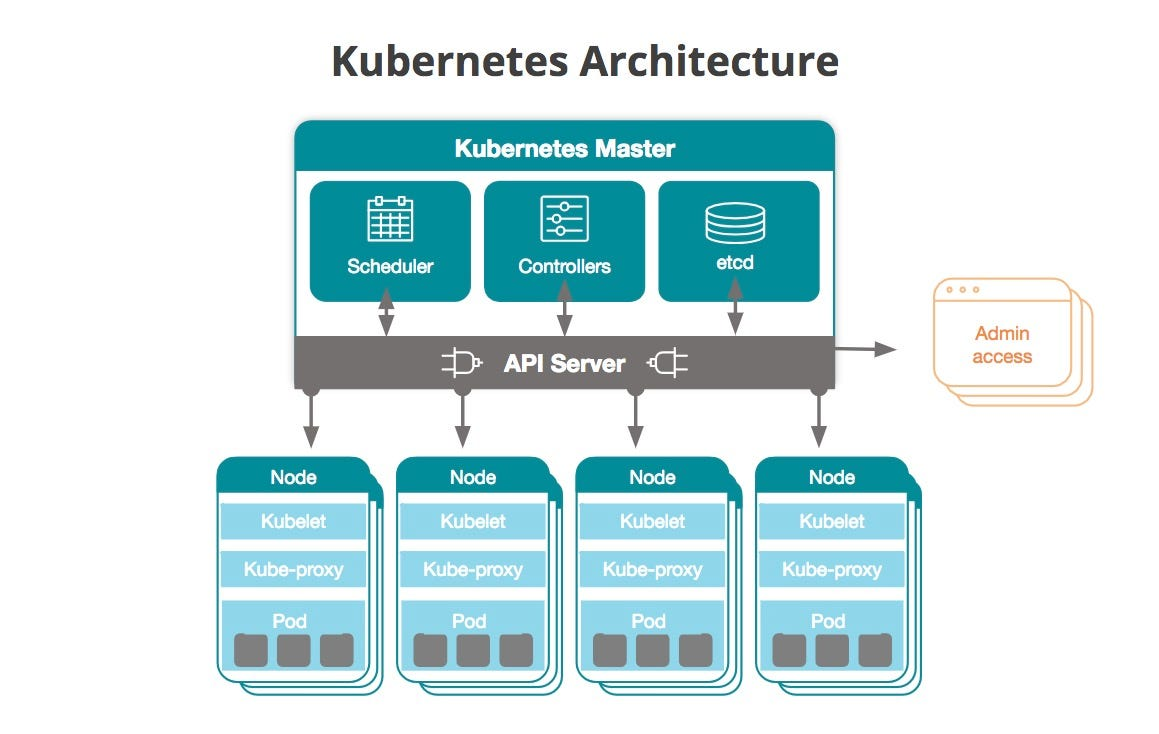
K8s 核心架构
控制面(Master Node):负责决策和调度
- API Server:所有操作的入口
- Scheduler:决定 Pod 跑在哪个 Node
- Controller Manager:维持期望状态(如副本数)
工作节点(Worker Node):真正跑容器的地方
- kubelet:节点代理,执行 Master 指令
- kube-proxy:网络代理,处理流量转发
- Container Runtime:容器运行时(Docker/containerd)
常用工作负载类型:
- Deployment:无状态应用(Web 服务、API)
- StatefulSet:有状态应用(数据库、消息队列)
- DaemonSet:每节点一个(日志、监控)
- Job/CronJob:批处理任务(数据计算、定时备份)
K8s 资源层级关系
Deployment ──► ReplicaSet ──► Pod
(声明期望状态) (保证副本数) (实际运行)
Service ──────► 提供稳定访问入口
ConfigMap ────► 配置注入
Node 只是”机器”,Pod 才是”应用”。K8s 自动把 Pod 调度到合适的 Node 上
Pod - K8s 最小调度单元
你很少直接写 Pod,因为 Deployment 已经包装了它。但要知道它存在,它是 K8s 最小调度单元。
Pod 特性:
- 一个 Pod 可包含多个容器(共享网络、存储)
- Pod 是临时的,IP 会变化,不要直接依赖 Pod IP
- 通常不直接创建 Pod,而是通过 Deployment 管理
ReplicaSet - 副本集
你很少直接写 ReplicaSet,因为 Deployment 已经包装了它。但要知道它存在。
graph TD A(Deployment<br/>管理发布策略) --> B(ReplicaSet<br/>管理副本数量) B --> C(Pod<br/>实际运行) C -.直接删 Pod<br/>会被重新创建.-> B
Deployment - 最常用的控制器
Deployment 是你最常用的资源,用于管理无状态应用。这是跑起第一个应用的完整配置:
# ========== 部署应用(Deployment) ==========
apiVersion: apps/v1 # API 版本
kind: Deployment
metadata:
name: my-app # 这个 Deployment 的名字
spec:
replicas: 2 # 期望运行 2 个副本(Pod)
selector: # 选择器:用于找到这个 Deployment 管理的 Pod
matchLabels:
app: my-app # 匹配标签为 app=my-app 的 Pod
template: # Pod 模板:定义 Pod 长什么样
metadata:
labels:
app: my-app # 给 Pod 打标签(必须和 selector 匹配)
spec:
containers: # 容器列表
- name: app # 容器名
image: nginx:latest # 使用的镜像(可以换成你自己的)
ports:
- containerPort: 80 # 容器内部监听的端口
---
# ========== 暴露服务(Service) ==========
apiVersion: v1 # API 版本
kind: Service
metadata:
name: my-app # Service 的名字
spec:
selector:
app: my-app # 选择标签为 app=my-app 的 Pod(和上面 Deployment 的 Pod 标签一致)
ports:
- port: 80 # Service 对外暴露的端口
type: LoadBalancer # 类型:LoadBalancer(云环境会自动分配公网 IP)快速部署命令:
# 保存上面的配置到 app.yaml,然后执行:
kubectl apply -f app.yaml
# 查看状态
kubectl get pods,deployments,services
# 查看详情和事件
kubectl describe deployment my-app
kubectl describe pod <pod-name>
# 扩缩容
kubectl scale deployment my-app --replicas=5
# 滚动更新
kubectl set image deployment/my-app app=nginx:1.21
# 回滚
kubectl rollout history deployment/my-app
kubectl rollout undo deployment/my-app
# 访问应用(如果是 LoadBalancer)
kubectl get svc my-app # 获取 EXTERNAL-IPService - 服务发现与负载均衡
为什么需要 Service?因为 Pod IP 会变,需要稳定的访问入口。
Service 类型:
- ClusterIP(默认):仅集群内访问
- NodePort:通过节点 IP + 端口访问
- LoadBalancer:云环境分配公网 IP
apiVersion: v1 # API 版本
kind: Service
metadata:
name: my-service # Service 的名字
spec:
selector:
app: MyApp # 选择标签为 app=MyApp 的 Pod(流量会转发到这些 Pod)
ports:
- protocol: TCP # 协议类型
port: 80 # Service 对外暴露的端口(其他服务访问这个端口)
targetPort: 9376 # Pod 内部的端口(流量最终转发到这里)
type: ClusterIP # 类型:ClusterIP(默认,仅集群内部可访问)常用命令:
# 查看服务
kubectl get services
# 端口转发(本地调试)
kubectl port-forward svc/my-service 8080:80ConfigMap 和 Secret - 配置管理
应用需要配置,但不应写死在镜像里。K8s 提供两种配置注入方式:
ConfigMap:存非敏感配置(数据库地址、功能开关) Secret:存敏感信息(密码、Token),base64 编码
# ========== ConfigMap:存储非敏感配置 ==========
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config # ConfigMap 的名字
data: # 键值对数据(明文存储,任何人都能看到)
DATABASE_URL: "mysql://db:3306" # 数据库地址
LOG_LEVEL: "info" # 日志级别
---
# ========== Secret:存储敏感信息 ==========
apiVersion: v1
kind: Secret
metadata:
name: db-secret # Secret 的名字
type: Opaque # 类型:Opaque(通用类型)
data: # 数据必须是 base64 编码
password: cGFzc3dvcmQxMjM= # 这是 "password123" 的 base64 编码
# 生成方法:echo -n "password123" | base64
# ========== 在 Pod 中使用 ConfigMap 和 Secret ==========
spec:
containers:
- name: app
image: myapp
envFrom: # 把整个 ConfigMap 注入为环境变量
- configMapRef:
name: app-config # 引用上面的 app-config
# Pod 里会自动有 DATABASE_URL 和 LOG_LEVEL 环境变量
env: # 单独注入某个 Secret 的值
- name: DB_PASSWORD # 环境变量名(Pod 里用这个名字)
valueFrom:
secretKeyRef:
name: db-secret # 引用上面的 db-secret
key: password # 取 Secret 中的 password 字段常用命令:
# 查看 ConfigMap 和 Secret
kubectl get configmaps,secrets
# 查看 ConfigMap 内容
kubectl describe configmap app-config
# 创建 Secret(从命令行)
kubectl create secret generic db-secret --from-literal=password=password123StatefulSet - 有状态应用
与 Deployment 的区别:
| 特性 | Deployment | StatefulSet |
|---|---|---|
| Pod 命名 | 随机(nginx-5d4f8b7c9d-abc12) | 有序(web-0, web-1, web-2) |
| 存储 | 共享/临时 | 每个 Pod 独立 PVC |
| 网络标识 | 临时 IP | 稳定 DNS(web-0.nginx) |
| 扩缩容 | 并行 | 有序(先删高序号) |
核心区别:Deployment 的 Pod 是”可替换”的(像外卖骑手, 谁都可以给客服送餐),StatefulSet 的 Pod 有”固定身份”(像银行柜员, 不同的银行柜员掌握的客户资料不一样,不能相互替换)。
以 Kafka 为例理解 StatefulSet:
Kafka 集群有 3 个 Broker,每个存储不同的数据分区:
kafka-0 → 存储分区 0(有固定 Broker ID = 0)
kafka-1 → 存储分区 1(有固定 Broker ID = 1)
kafka-2 → 存储分区 2(有固定 Broker ID = 2)
如果用 Deployment:
- ❌ Pod 重启后名字变了(kafka-abc → kafka-xyz),Broker ID 乱了
- ❌ 每个 Pod 的数据分区对应关系丢失
用 StatefulSet:
- ✅ Pod 重启后还是
kafka-0,Broker ID 保持 0 - ✅ 每个 Pod 绑定独立 PVC(kafka-data-0、kafka-data-1)
- ✅ 可以通过稳定域名访问:
kafka-0.kafka-headless.default.svc.cluster.local
典型用途:
- 数据库(MySQL、PostgreSQL、MongoDB)
- 消息队列(Kafka、RabbitMQ)
- 分布式协调(Etcd、ZooKeeper)
持久化存储(PersistentVolume): StatefulSet 通常需要持久化数据,K8s 提供了 PV/PVC 机制:
- PV(PersistentVolume):集群中的存储资源(管理员创建)
- PVC(PersistentVolumeClaim):用户的存储请求(自动绑定 PV), 用人话说:PVC 就是你向 K8s 申请一块”硬盘”的单子。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc # PVC 的名字
spec:
accessModes: # 访问模式
- ReadWriteOnce # 只能被一个 Node 以读写模式挂载(适合数据库)
# 其他选项:ReadOnlyMany(多节点只读)、ReadWriteMany(多节点读写)
resources:
requests:
storage: 10Gi
# StatefulSet 会自动为每个 Pod 创建独立的 PVC
# 比如有 3 个副本,就会创建 mysql-pvc-0、mysql-pvc-1、mysql-pvc-2DaemonSet - 守护进程
每个 Node 上跑且仅跑一个 Pod。
典型用途:
- 日志收集(Fluentd、Filebeat)
- 监控代理(Prometheus Node Exporter)
- 网络代理(Calico、Cilium 节点组件)
常用命令:
# 查看 DaemonSet
kubectl get daemonsets
# 查看 DaemonSet 的 Pod(每个 Node 一个)
kubectl get pods -o wideJob / CronJob - 批处理
Job:运行一次的任务 CronJob:定时运行的任务
CronJob 不直接创建 Pod,它创建 Job,Job 再创建 Pod:
graph TD A(CronJob<br/>定时规则) -->|每分钟检查<br/>触发| B(创建 Job<br/>data-backup-29010234) B --> C(创建 Pod<br/>运行任务) C --> D(Pod 完成 →<br/>Job 标记完成)
# ========== Job:运行一次的任务 ==========
apiVersion: batch/v1
kind: Job
metadata:
name: pi # Job 的名字
spec:
template: # Pod 模板
spec:
containers:
- name: pi # 容器名
image: perl:5.34 # 使用 perl 镜像
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] # 计算圆周率
restartPolicy: Never # 失败后不重启(Job 会重新创建 Pod)
backoffLimit: 4 # 最多重试 4 次,超过就标记为失败
---
# ========== CronJob:定时运行的任务 ==========
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello # CronJob 的名字
spec:
schedule: "*/1 * * * *" # Cron 表达式:每分钟运行一次
# 格式:分 时 日 月 周
# 示例:"0 2 * * *" = 每天凌晨 2 点
jobTemplate: # Job 模板(CronJob 会按计划创建 Job)
spec:
template: # Pod 模板
spec:
containers:
- name: hello # 容器名
image: busybox:1.28 # 使用轻量级镜像
command: ['sh', '-c', 'echo Hello!'] # 打印 Hello
restartPolicy: OnFailure # 失败后重启容器常用命令:
# 查看 Job 和 CronJob
kubectl get jobs,cronjobs
# 查看 Job 的 Pod
kubectl get pods -l job-name=pi
# 查看 CronJob 历史
kubectl get jobs --watch
# 手动触发 CronJob
kubectl create job --from=cronjob/hello manual-jobHPA - 自动伸缩
HPA(Horizontal Pod Autoscaler)根据 CPU/内存使用率自动调整 Pod 数量。
apiVersion: autoscaling/v2 # API 版本
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa # HPA 的名字
spec:
scaleTargetRef: # 要伸缩的目标
apiVersion: apps/v1
kind: Deployment # 针对 Deployment
name: my-app # 目标 Deployment 的名字
minReplicas: 2 # 最少保持 2 个 Pod
maxReplicas: 10 # 最多扩容到 10 个 Pod
metrics: # 指标列表
- type: Resource # 指标类型:资源(CPU/内存)
resource:
name: cpu # 监控 CPU 使用率
target:
type: Utilization # 目标类型:使用率百分比
averageUtilization: 70 # 当平均 CPU 使用率超过 70% 时扩容
# 低于 70% 时缩容(有冷却时间,防止频繁变化)快速创建 HPA:
kubectl autoscale deployment my-app --cpu-percent=70 --min=2 --max=10
# 查看 HPA 状态
kubectl get hpa
# 查看 HPA 详情
kubectl describe hpa my-app-hpa其他常用命令
# 查看集群节点
kubectl get nodes
# 查看所有资源
kubectl get all
# 查看日志
kubectl logs <pod-name> -f --tail=100
# 进入容器调试
kubectl exec -it <pod-name> -- /bin/sh
# 查看资源详情和事件(排查问题)
kubectl describe <resource> <name>