假设双11,凌晨3点你被叫醒。通知应用卡死了,用户开始投诉。你怎么开始排查?ssh 到服务器,用命令查看机器和数据库的性能?
在云原生时代,我们不需要像传统那样,进服务器敲命令。例如GCP 提供了强大的可视化监控工具,非常方便帮助,我们快速查看机器的状态。
GCP Console → SQL → [你的实例],有两个关键入口:
- System Insights:看硬件(CPU、内存、磁盘)
- Query Insights:看具体哪条 SQL 出了问题
几个最常看的指标
Cloud SQL 指标很多,但高频使用的有下面几个。
CPU Utilization
数据库执行查询时消耗的 CPU 资源占比。每当执行一条 SQL,数据库需要:
- 解析 SQL 语法
- 制定执行计划
- 扫描数据(从内存或磁盘)
- 排序、聚合、JOIN 等计算
这些操作都需要 CPU 资源。
健康标准: 保持在 60% 以下,CPU 飙升本身只是症状,不是根因。需要结合其他指标判断:
- 不伴随高 Read IOPS:计算密集型操作,比如复杂正则、大量排序
ORDER BY、或者应用代码死循环 - 伴随高 Read IOPS:全表扫描 Sequential Scan,CPU 在疯狂处理从磁盘读上来的海量数据
Read/Write IOPS
硬盘每秒处理多少个 I/O 操作(Input/Output Operations Per Second)。
PostgreSQL 执行查询时,如果数据不在内存(Buffer Cache)中,就必须从磁盘读取。每次读取一个数据块(默认 8KB),就算一次 Read IOPS。
-- 有索引:只读几个数据块
SELECT * FROM orders WHERE id = 12345; -- 2-3 次 Read IOPS
-- 全表扫描:读取整张表
SELECT * FROM orders WHERE status = 'pending'; -- 10000+ Read IOPS健康标准:根据磁盘容量不同,IOPS 上限不同。关键是看趋势,突然激增说明有问题。
IOPS 异常的原因:
- Read IOPS 激增:Buffer Cache 缓存不足,频繁读盘。最常见是全表扫描或缺索引
- Write IOPS 激增:大量写入操作,或者内存不够用,数据库在磁盘上做排序(External Sort)
Active Connections
当前有多少个应用连接到数据库。每个 API 请求通常会从连接池获取一个连接,执行 SQL,然后归还。
健康标准: 取决于数据库配置 max_connections,通常保持在 50-70% 以下
Connection Storm 发生时,第一反应通常是”流量增加了”。但更常见的原因是数据库变慢了。
逻辑很简单:SQL 慢 → 线程卡住不释放 → 新请求建立新连接 → 连接数暴涨 → 负载更高 → 更慢 → 雪崩。
连接数达到 max_connections 上限,新连接会失败,报错 FATAL: remaining connection slots are reserved,用户看到 502。
连接数暴涨通常是:
- 慢 SQL 导致连接长时间占用
- 应用层连接泄露(获取连接后忘记关闭)
- 突发流量(真的是业务增长)
Memory Usage
数据库使用的内存占比。PostgreSQL 会尽可能多地使用内存做缓存(Buffer Cache),把热数据放在内存里,避免读盘。
健康标准: 60-90% 都是正常的,PostgreSQL 设计就是”吃掉所有空闲内存做缓存”,这个指标容易被误解,内存使用率 90% 不一定有问题。真正要担心的是:
- 数据库开始使用 Swap:内存真的不够了,操作系统把内存数据换到磁盘,性能断崖式下降
- 日志出现 OOM 或
Kill process:内存耗尽,进程被杀
没有 Swap 和 OOM,内存 90% 是正常的。
Byte Throughput
数据库每秒处理多少字节的数据(包括读和写)。
健康标准: 没有绝对值,关键是结合 CPU 使用率判断
这个指标用来区分”代码问题”还是”业务增长”:
- CPU 高 + 吞吐量低:数据库在努力工作,但没干多少活。典型是低效 SQL,查半天只返回几行
- CPU 高 + 吞吐量高:数据库在处理大量真实数据。可能是业务增长,考虑扩容或分库分表
PostgreSQL 特有指标
除了上面 5 个,PostgreSQL 还有几个容易被忽略但很致命的指标。
Transaction ID Utilization
PostgreSQL 用 32 位事务 ID (TXID) 跟踪事务,最多 2^31 个。用完后,数据库进入保护模式,停止写入。
健康标准:保持在 50% 以下
每当我们执行任何写操作(INSERT、UPDATE、DELETE)时,PostgreSQL 会:
BEGIN; -- 开启事务,分配 TXID = 1001
INSERT INTO users ...; -- PostgreSQL 内部记录这一行是由 TXID 1001 创建的
COMMIT; -- 提交,TXID 1001 完成
BEGIN; -- 下一个事务,分配 TXID = 1002
UPDATE orders ...; -- PostgreSQL 内部记录这一行由 TXID 1002 修改
COMMIT;PostgreSQL 内部记录这一行由 TXID 1002 修改COMMIT;- 每个事务(不管是 BEGIN…COMMIT 还是单条 SQL)都会消耗一个 TXID
- TXID 是全局递增的,2^31 个用完就没了
你需要做什么?
通常不需要人工干预, PostgreSQL 的 autovacuum 进程会自动清理,保持 TXID 在安全范围, 所以你只需要确保 autovacuum 没有被禁用,即可
如果出现问题:
- 检查是否有长事务:查询运行超过几小时甚至几天的事务
- 立即执行
VACUUM FREEZE来回收 TXID
Wait Events
数据库在处理查询时,大部分时间不是在”干活”,而是在”等”。Wait Events 告诉你它在等什么。
IO 等待:等磁盘
你执行了一个查询,PostgreSQL 需要从表里读取数据。如果数据在内存(Buffer Cache)里,毫秒级返回。如果不在,就得从磁盘读。
SELECT * FROM orders WHERE user_id = 12345;- 如果有索引,只读几个数据块,等待时间短
- 如果全表扫描,读几万个数据块,
DataFileRead等待飙升
IO 等待高通常是两种情况:
- 缓存不足,热数据放不下,频繁读盘
- 查询低效,全表扫描或缺索引
Lock 等待:等别人释放锁
两个事务同时操作同一行数据,后来的那个必须等前面的完成。
场景:电商秒杀,1000 个用户同时买最后一件商品。
-- 事务 A:用户 1 下单
BEGIN;
UPDATE products SET stock = stock - 1 WHERE id = 999; -- 获得行锁
-- ... 处理支付逻辑(假设耗时 2 秒)
COMMIT; -- 释放锁
-- 事务 B:用户 2 下单(几乎同时发起)
BEGIN;
UPDATE products SET stock = stock - 1 WHERE id = 999; -- 等待事务 A 释放锁事务 B 会在 Lock 等待,直到事务 A 完成。如果事务 A 迟迟不提交(比如代码卡在支付接口调用),所有后续事务都在排队。
Lock 等待高,通常是:
- 有长事务持着锁不放
- 事务里做了耗时操作(调用外部 API、复杂计算)
CPU 等待:等 CPU 调度
数据库准备好了,但 CPU 在处理其他任务,查询在排队等 CPU 时间片。
这种情况少见,但可能发生在:
- 机器上运行了其他高 CPU 程序
- CPU 核心数不够,数据库线程排队
- Linux 调度器配置不当
CPU 等待高但 CPU 利用率不高,说明调度出了问题。
Deadlock Count
两个或多个事务互相等待对方持有的锁。PostgreSQL 会自动检测并终止其中一个。
频繁死锁通常是:
- 应用以不同顺序访问表
- 事务持锁时间太长
- 并发更新同一批数据
PostgreSQL 日志里有具体死锁详情。
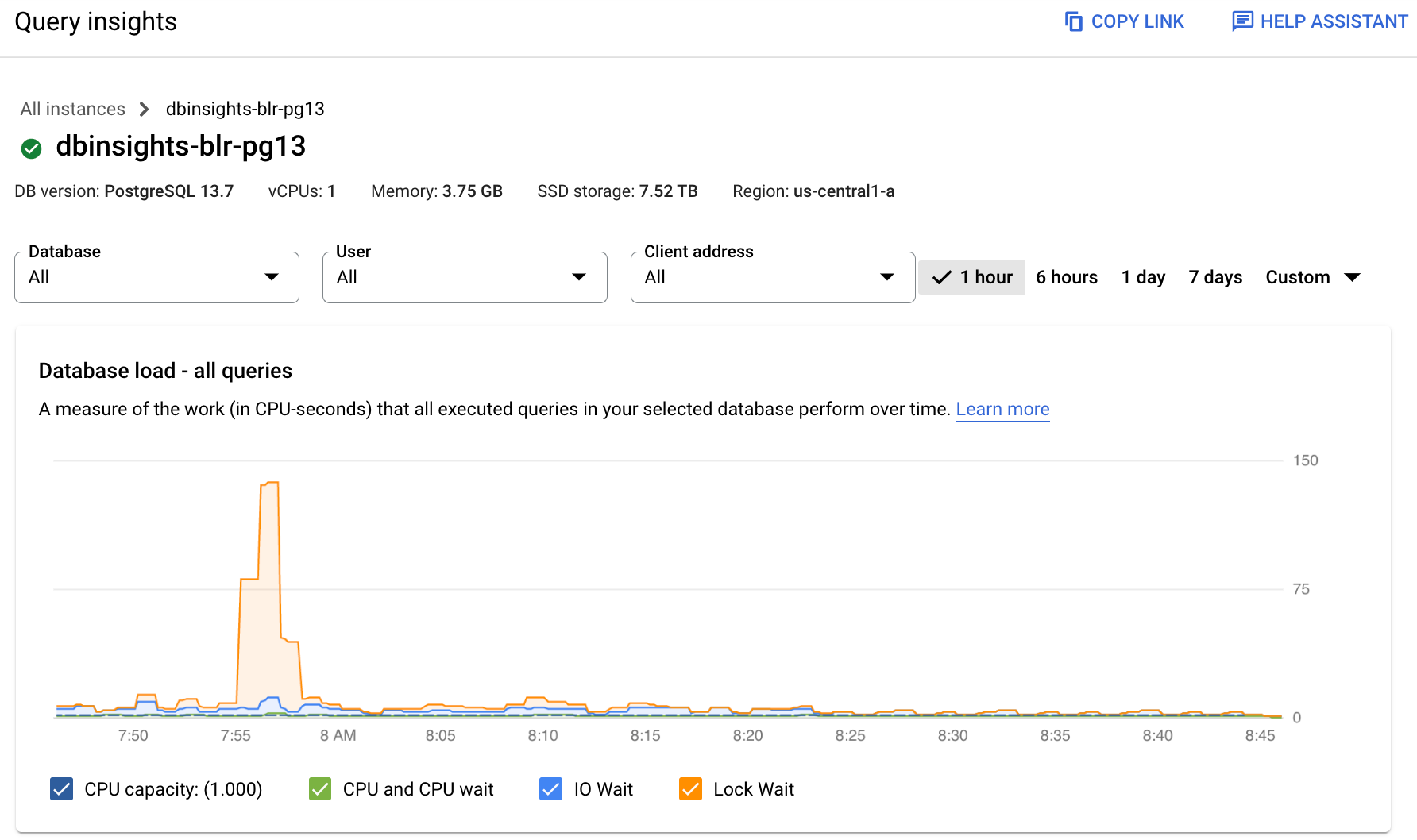
Query Insights
GCP 最强大的功能。
Top Queries
按 “Load by total time” 排序,最烂的 SQL 在第一位。
关键信息:
- Avg Execution Time:单次平均耗时
- Invocations:执行次数
- Rows Returned:返回数据量
查询可能单次不慢,但调用次数高,累计负载就大。反之,单次很慢,调用不多,也需要优化。
Query Plans
自动采样查询计划。
能看到:
- 是否用了索引(Index Scan vs Seq Scan)
- JOIN 的顺序和方式(Nested Loop vs Hash Join)
- 预估行数 vs 实际行数(相差大说明统计信息过期)
企业 Plus 版有索引顾问,自动推荐该创建哪些索引。
应用标记 (Tags)
Query Insights 显示一条慢查询占用了 80% 的数据库负载。但你有 10 个微服务,共用一个数据库,上百个 API 接口,不知道是哪个发起的。
sqlcommenter 可以在每条 SQL 后面自动加上注释,标记这条查询来自哪里。
# 使用 sqlcommenter (以 Python Django 为例)
# 执行查询时,自动添加注释
query = "SELECT * FROM orders WHERE user_id = 123"
# 实际发送到数据库的 SQL:
# SELECT * FROM orders WHERE user_id = 123
# /*controller='OrderController',route='/api/orders',action='list'*/GCP Query Insights 会解析这些注释,按标签分组:
- controller=‘OrderController’:订单控制器发起的所有查询
- route=‘/api/orders’:订单列表接口发起的所有查询
- action=‘list’:列表操作发起的所有查询
没有标记:只能看到慢查询是 SELECT * FROM users WHERE email = ?,但不知道哪个服务在调用。
有标记:直接看到是 service='notification-service' 发起的,定位到通知服务在批量查询用户邮箱,没走索引。
快速排查
80% 的性能问题都来自这 4 个原因:
graph TB Start([应用出现性能问题]) --> CheckCPU{CPU > 70%?} CheckCPU -->|是| CheckWait{查看 Wait Events} CheckCPU -->|否| CheckConn{连接数接近上限?} CheckWait -->|IO Wait 高<br/>Read IOPS 高| SeqScan[全表扫描] CheckWait -->|Lock Wait 高| LockWait[锁等待] SeqScan --> Fix1[Query Insights 找慢查询<br/>EXPLAIN 看执行计划<br/>添加索引] LockWait --> Fix2[找未提交的长事务<br/>缩短事务持锁时间] CheckConn -->|是| SlowSQL[慢 SQL 导致连接堆积] CheckConn -->|否| AppLayer[应用层问题] SlowSQL --> Fix3[Query Insights 找慢查询<br/>优化 SQL<br/>引入 PgBouncer] style Start fill:#e7f5ff style SeqScan fill:#ffe3e3 style LockWait fill:#ffe3e3 style SlowSQL fill:#ffe3e3 style Fix1 fill:#d3f9d8 style Fix2 fill:#d3f9d8 style Fix3 fill:#d3f9d8
速查表
| 现象 | 看什么指标 | 可能原因 | 怎么办 |
|---|---|---|---|
| 应用卡顿 | CPU 高 + Read IOPS 高 + IO Wait 高 | 全表扫描 | Query Insights 找慢查询,EXPLAIN 分析,加索引 |
| 应用卡顿 | CPU 高 + IOPS 低 + CPU Wait 高 | 计算密集 SQL | 检查复杂运算、正则、JSON 解析,考虑缓存 |
| 应用卡顿 | CPU 高 + Lock Wait 高 | 锁等待 | 找未提交的长事务,缩短事务持锁时间 |
| 服务 502 | Active Connections 满 + 有慢 SQL | 连接堆积 | 优化慢 SQL 或加 PgBouncer |
| 数据库只读 | Transaction ID Utilization > 75% | TXID 耗尽 | 立即执行 VACUUM,检查长事务 |
关键:看 Wait Events 类型, CPU 高不代表有问题,重点是数据库在等什么
- IO Wait:在等磁盘读写,通常是全表扫描或缺索引
- CPU Wait:在做计算,检查是否有复杂运算
- Lock Wait:在等锁释放,找长事务
一些经验
建立基线, 记录正常时期的指标:
- CPU:平时 30-40%
- Active Connections:平时 50-100
- Read IOPS:平时 1000-2000
- Transaction ID:平时 20-30%
设置告警
| 指标 | 严重阈值 | 持续时间 |
|---|---|---|
| CPU Utilization | > 90% | 5 分钟 |
| Active Connections | > 90% max_connections | 3 分钟 |
| Transaction ID Utilization | > 75% | 立即 |